아하랩스 팀이 AI 모델의 학습 결과를 분석하고 성능을 개선하는 방법을 알아보세요
이두희 | 아하랩스 AI 리서처

AI 모델의 학습 성능을 높이려면 모델 학습 결과에 대한 분석이 가능해야 합니다. 이번 아티클에서는 아하랩스 AI 팀이 모델의 성능을 평가하는 방법에 대해 자세히 알려드릴게요!
1. 컨퓨전 매트릭스(classification, segmentation, anomaly detection)
아하랩스는 모델 학습 후, 성능을 정밀하게 분석하여 개선 방향을 도출합니다. 이를 위해 컨퓨전 매트릭스(Confusion Matrix) 를 활용합니다. 컨퓨전 매트릭스는 모델의 예측 결과와 실제 라벨을 비교하여 성능을 분석하는 도구입니다.
분류(Classification), 분할(Segmentation), 이상탐지(Anomaly Detection) 모델을 생성한 경우, 과검 미검 그리고 컨퓨전 매트리스가 나오게 됩니다.
컨퓨전 매트릭스를 통해 다음과 같은 요소를 확인합니다.
- 과검(False Positive) : 모델이 결함이라고 판단했지만 실제로 정상인 경우
- 미검(False Negative) : 모델이 결함을 검출하지 못한 경우
아래 그림에서 컨퓨전 매트릭스를 활용하면, 모델이 어떤 유형의 데이터를 잘못 예측했는지 한눈에 확인할 수 있습니다. 이를 기반으로 라벨링 방식 조정, 데이터 보강 등의 개선 방향을 도출합니다.
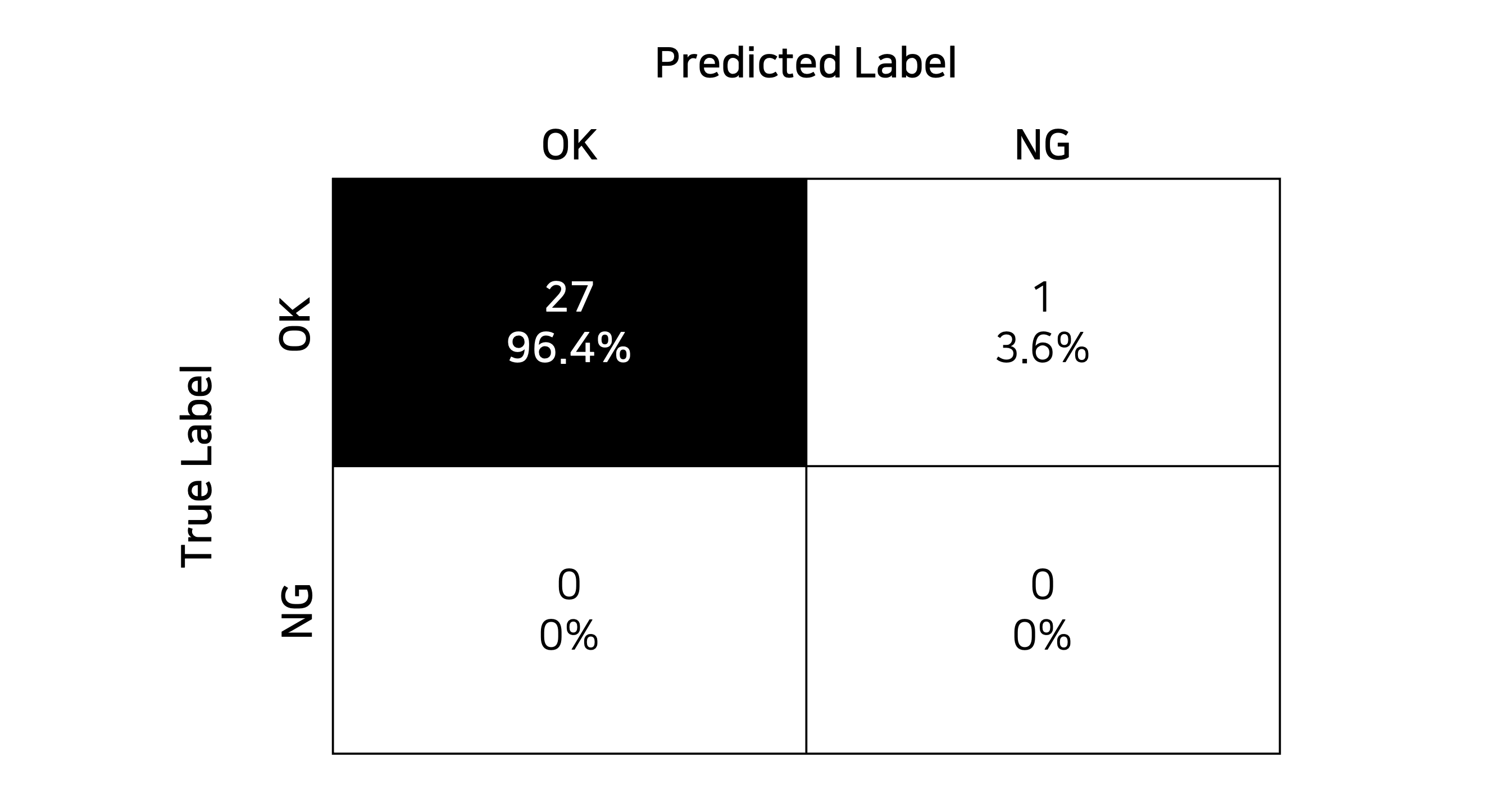
컨퓨전 매트릭스를 활용하면 모델이 어떤 유형의 데이터를 잘못 예측했는지 한눈에 확인할 수 있습니다. 왼쪽 상단은 정상품을 정상으로 맞게 예측한 경우, 오른쪽 상단은 정상품을 불량품으로 잘못 예측한 경우(과검), 왼쪽 하단은 불량품을 정상으로 잘못 예측한 경우(미검), 오른쪽 하단은 불량품을 불량으로 맞게 예측한 경우입니다. Image Credit: AHHA Labs
2. 바운딩 박스(object detection)
객체 검출(Object Detection) 모델의 성능을 평가할 때는 바운딩 박스(Bounding Box) 의 정확도를 확인해야 합니다. 다음과 같은 지표를 활용하여 모델 성능을 분석합니다.
(1) 바운딩 박스(좌표)
- IoU(Intersection over Union, 교차 비율) : 모델이 예측한 바운딩 박스와 실제 바운딩 박스의 겹치는 정도를 나타냅니다.
- IoU 값이 0.9에 가까우면 예측이 매우 정확한 것이고,
- IoU 값이 0.5면 절반 정도 일치,
- IoU 값이 0이면 예측이 전혀 맞지 않는 경우입니다.
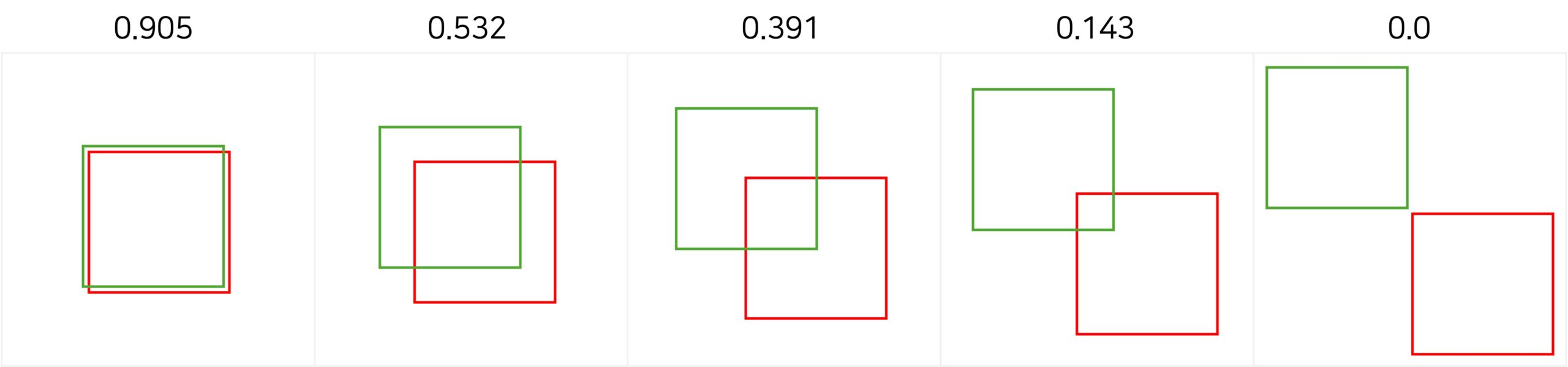
IoU(Intersection over Union, 교차 비율)은 모델이 예측한 바운딩 박스와 실제 바운딩 박스의 겹치는 정도를 나타냅니다. 값이 0.9에 가까우면 예측이 매우 정확한 것이고, 값이 0이면 예측이 전혀 맞지 않는 경우입니다. Image Credit: AHHA Labs
- mAP(mean Average Precision) : IoU 값이 0.3 이상, 0.5 이상, 0.9 이상인 경우 각각의 AP 값을 구한 후 평균을 내어 모델의 전반적인 성능을 평가합니다. IoU와 클래스 정보 모두를 얻을 수 있는 지표입니다.
(2) 바운딩 박스(클래스)
다음으로는 바운딩 박스 클래스에 대한 정보를 확인할 수 있는 평가 지표입니다. 총 세 개의 지표로 구성되어 있으며, Recall(재현율), Precision(정밀도), F1-score 를 활용하여 모델 성능을 분석합니다.
아래 그림에서 보이는 것처럼,
- A : 정답(실제 라벨)
- B : 모델이 예측한 값
이때, 정답과 모델이 예측한 값이 일치하는 부분은 b, 정답이지만 모델이 검출하지 못한 부분은 a, 모델이 잘못 예측한 값은 c로 정의할 수 있습니다.
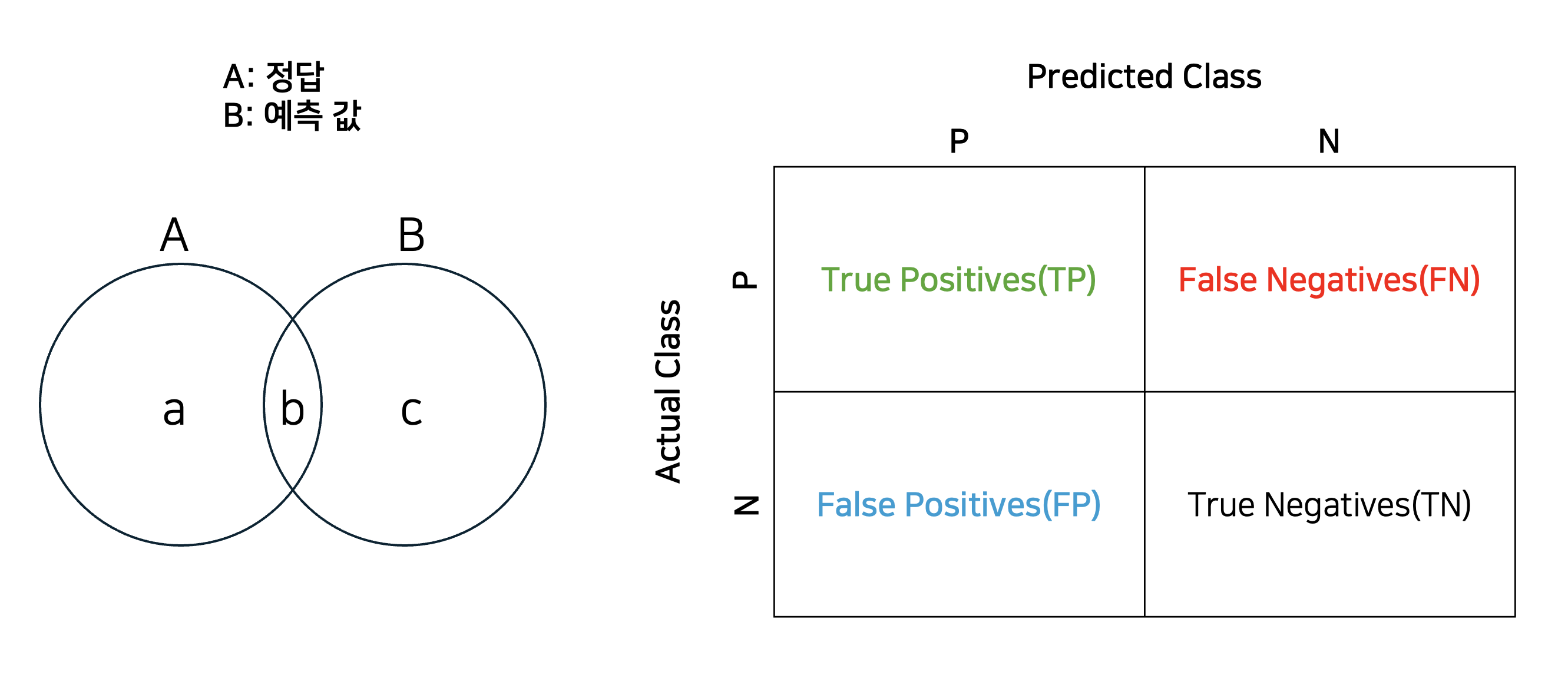
바운딩 박스 클래스에 대한 평가 지표는 총 세 개로 구성되어 있으며, Recall(재현율), Precision(정밀도), F1-score 를 활용하여 모델 성능을 분석합니다. Image Credit: AHHA Labs
- Recall (재현율) = b / (a + b)
- TP / (TP+FN)
- 정답으로 라벨링된 데이터(A) 중에서 모델이 검출한 비율을 의미합니다.
- 즉, 실제 결함 중에서 몇 개를 제대로 찾았는지를 나타내며, false negative(미검) 값을 포함합니다.
- 리콜이 낮다면 모델이 결함을 놓치는 비율이 높아, 실제 사용 환경에서 중요한 결함을 검출하지 못할 가능성이 있습니다.
- Precision (정밀도) = b / (b + c)
- TP / (TP+FP)
- 모델이 검출한 바운딩 박스 중에서 실제 결함과 일치하는 비율을 의미합니다.
- false positive(과검) 값을 포함하며, 정밀도가 낮다면 모델이 잘못된 결함을 많이 검출하는 문제가 발생할 수 있습니다.
- F1-score = (2 × Recall × Precision) / (Recall + Precision)
- 리콜과 정밀도의 균형을 평가하는 지표로, 두 지표가 함께 고려되므로 보다 종합적인 성능 평가가 가능합니다.
- 특히 클래스 불균형(Class Imbalance)이 있는 경우, 단순한 정밀도나 재현율보다 F1-score가 더 적절한 평가 지표가 될 수 있습니다.
정밀도와 재현율을 함께 분석하면 모델이 과검(FP)과 미검(FN) 문제를 얼마나 잘 해결하고 있는지 판단할 수 있습니다. 아하랩스는 이러한 분석을 통해 고객의 요구사항에 맞게 데이터셋을 최적화하고, 모델이 실제 사용 환경에서 높은 정확도를 유지할 수 있도록 지원합니다.
3. 과적합(Overfitting) 문제
AI 모델 학습 과정에서 과적합(Overfitting) 은 모델의 일반화 성능을 저하시킬 수 있는 주요 문제 중 하나입니다. 아하랩스는 학습이 완료된 후 리포트를 분석하여, 모델이 훈련 데이터뿐만 아니라 새로운 데이터에서도 좋은 성능을 낼 수 있도록 조정합니다.
(1) Loss(손실) 값과 트레이닝/밸리데이션 데이터셋 비교
아래 그림에서 보이는 것처럼, 모델 학습 후 Loss(손실) 그래프를 통해 학습이 적절히 진행되었는지를 확인할 수 있습니다.
- Loss란?
- Loss는 모델이 예측한 값과 실제 정답 간의 오차를 의미합니다.
- Loss 값이 낮을수록 모델이 정답에 가까운 출력을 내고 있다는 뜻입니다.
- 트레이닝 데이터셋(Training Dataset) vs. 밸리데이션 데이터셋(Validation Dataset)
- 트레이닝 데이터셋은 모델을 학습시키는 데 사용되는 데이터입니다.
- 밸리데이션 데이터셋은 학습 중간에 모델의 성능을 평가하는 데이터로, 학습에는 사용되지 않습니다.
모델이 학습 데이터에만 치우쳐 학습되지 않도록, 밸리데이션 데이터셋을 사용하여 새로운 데이터에서도 성능이 유지되는지 확인하는 것이 중요합니다.
(2) 과적합 판단 방법 – Loss 그래프 분석
아래 그림에서 확인할 수 있듯이, Loss 그래프를 활용하여 학습 진행 상황을 분석할 수 있습니다.
- 정상적인 학습:
- 트레이닝 Loss와 밸리데이션 Loss가 동시에 감소하는 경우, 모델이 정상적으로 학습되고 있는 것입니다.
- 이 경우 과적합 없이 모델이 적절히 최적화되고 있다고 볼 수 있습니다.
- 과적합(Overfitting) 발생:
- 트레이닝 Loss는 계속 감소하지만, 어느 순간부터 밸리데이션 Loss가 다시 증가하는 경우 과적합이 발생한 것입니다.
- 이는 모델이 학습 데이터에 너무 최적화되어, 새로운 데이터(밸리데이션 데이터)에서는 제대로 동작하지 못하는 상태를 의미합니다.
- 과적합이 발생하면, 모델이 특정 패턴만 기억하고 일반적인 데이터에 대해서는 예측 성능이 떨어지게 됩니다.
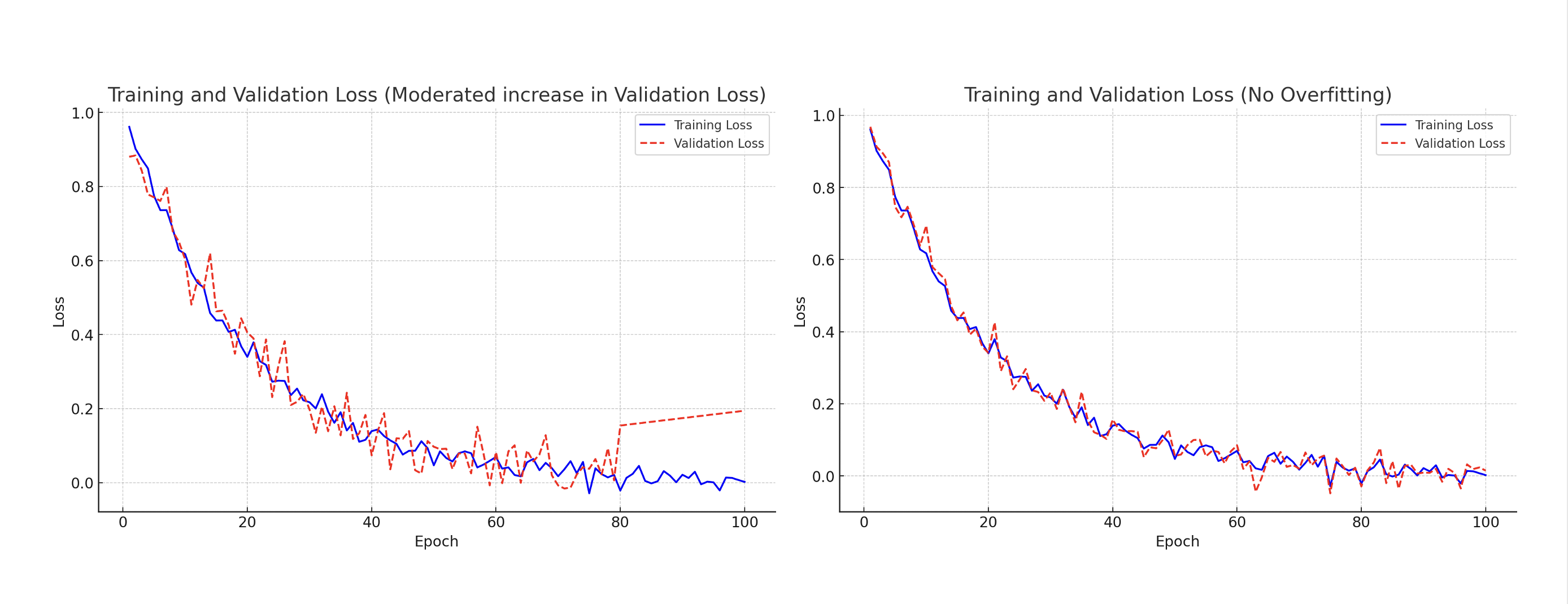
Loss는 모델이 예측한 값과 실제 정답 간의 오차를 의미하고, Loss 값이 낮을수록 모델이 정답에 가까운 출력을 내고 있다는 뜻입니다. 만약 트레이닝 Loss는 계속 감소하지만, 어느 순간부터 밸리데이션 Loss가 다시 증가하는 경우 과적합이 발생한 것입니다. Image Credit: AHHA Labs
이러한 과적합 문제를 해결하기 위해 아하랩스는 학습 데이터의 다양성을 확보하고, 적절한 모델 웨이트(Weights) 저장 시점을 결정합니다. 밸리데이션 Loss가 최소가 되는 지점을 기준으로 모델의 가중치를 저장하면, 과적합을 방지하면서 최적의 성능을 유지할 수 있습니다.
아하랩스는 Loss 그래프를 정밀하게 분석하여, 과적합이 발생하지 않는 최적의 모델을 구축합니다. 고객이 원하는 정확도를 만족하면서도, 실제 운영 환경에서 높은 성능을 유지하는 AI 모델을 제공하기 위해 지속적으로 학습 프로세스를 개선하고 있습니다.